Building a library of STACK functions for use throughout a linear algebra course
Luke Longworth
Introduction
I have been developing questions and quizzes with STACK for the University of Canterbury, New Zealand, since the end of 2020, and have seen several courses develop original quizzes from scratch in that time. When writing large amounts of questions in a short space of time, especially when multiple people are working on it, I find myself encountering two problems frequently:
- The way students must input their answers differs from question to question within a course. For example, should a student give a list of values
[1,2,3], a tuple(1,2,3), something more complicated like a matrixmatrix([1],[2],[3]), or use a matrix input type? - I find myself asking myself the question "I know I wrote some code to solve this a few months ago, where did that question go...?" frequently. This problem is twofold: I am needing to copy code between questions (making debugging a nightmare if I find a problem in either place later), and I can't find the working code when I need it!
These problems cannot be solved easily for existing large question banks, nor do I think that the former is inherently a "problem" anyway (it's more that I would like to have a set of rules/standards to break rather than no rubric at all). However, when constructing new quizzes, we can design with these considerations in mind to create a more internally-consistent product.
At the end of 2023, the creation of quizzes for our 200-level engineering linear algebra course was sanctioned. This is a course I had been closely involved with for the past few years, and was the largest advance warning I'd ever received for a course wanting to implement new quizzes. I took this as an opportunity to design quizzes "properly" and have been attempting to avoid the above issues.
My solution was to create a new Maxima file, linearalgebra.mac that I could include in my new questions by running stack_include_contrib('linearalgebra.mac'); at the beginning of each question which would contain various helper functions and could be easily updated to service an entire question bank at once.
At time of writing (June 2024), this file is now mostly complete and the course question bank is being written. This case study serves to document the process I went through, briefly describe the contents of the file, and to reflect on the successes and failures encountered so far. The intention is to publish the file to STACK at the end of 2024 once it has been used (and thus stress-tested) in a real course, and then any user can use it with stack_include_contrib by including within the CAS-logic.
Course Background
The engineering linear algebra course, EMTH211, is a second-year compulsory course for our electronic and mechatronic engineering students at University of Canterbury, New Zealand. It has a greater focus on numerical linear algebra than the other 200-level course on offer, MATH203, and has a large Python-coding component in lectures and assessment. Expected prior knowledge includes basic matrix arithmetic, Gaussian elimination, determinants, and eigenproblems.
Students enrolled in this course have been using STACK for at least 3 semesters prior and are familiar with the way that we use quizzes and STACK. The course currently focuses on tutorials that encourage hand-working and Python coding, and are marked for engagement rather than correctness. The first major piece of assessment is not returned until week 7, so students who do not self-assess well may not have had any feedback on their ability to correctly solve problems until the course is over halfway through. The hope is that the introduction of regular quizzes will keep students engaged, help them to identify misconceptions, and let them practice basic computations.
EMTH211 is a good candidate for this type of project because of its status as a 200-level linear algebra course. There are lots of regularly used routines in linear algebra, so code-sharing is commonplace. The existing linear algebra support in Maxima is mostly concerned with manipulating matrices, with some other packages doing very specific things (such as diag for computing Jordan normal forms, or lapack for running numerical routines). This leaves plenty of room for functions that are widely applicable, simple, and useful. Additionally, these students have experience with STACK and will hopefully be comfortable with things like new input types.
What was my writing process?
My writing process is not particularly good practice and wouldn't scale well, but it has worked for me and is entirely in-browser. This suits me, as I use a remote desktop connection at work and don't have much control over my own installs and settings.
1. Overarching structure
I first began by planning the quiz structure on paper. This included logistical questions (when will they be due), content questions (which pieces of the curriculum work well in STACK) and pedagogical questions (how do I want/expect students to engage with these quizzes as learning activities?). I decided that my goal was to write questions that would differentiate themselves from tutorials and assignments (which are more focused on key concepts and coding) by focusing the quiz questions on producing correct numerical results. After settling on fortnightly quizzes of approximately 8 questions per quiz, I identified 4 key computations for each week, leading to approximately 48 individual types of computation (as well as first year revision for early in the semester).
Once I knew the types of questions I was writing, I began to write functions that felt like they would be useful when developing one or more of the questions I had planned. Initially I began working in a single STACK question that included all of the functions in one place but this became very clunky when the test cases piled up and slowed down the compilation significantly. Next, I moved my work to GitHub (see below).
I wrote some questions as I went, mostly to test out my new vector notation, but most of the questions have not yet been written. I will discuss this more below.
2. GitHub
If you're new to GitHub (I certainly am) here is a rundown on my process. - From the STACK home on GitHub click the Fork button to create your own copy of STACK.
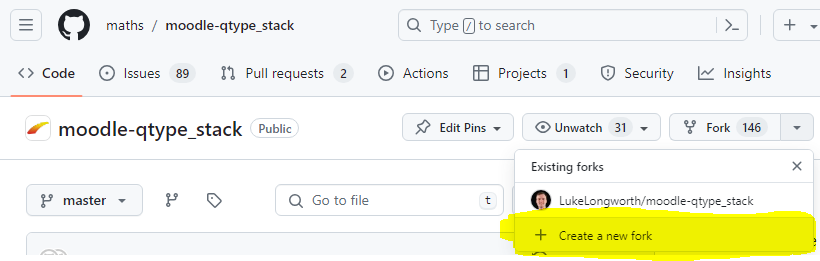
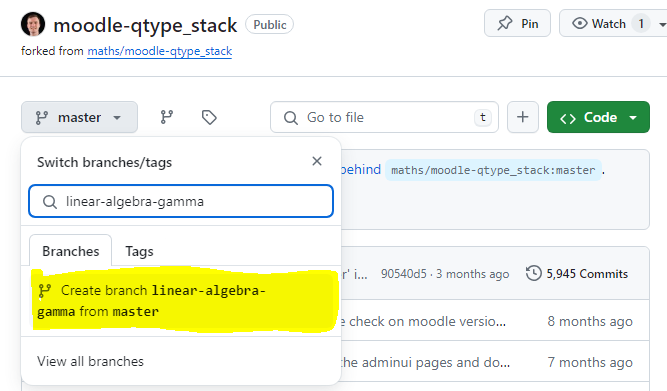
- Go to the fork you've created and create a new branch, either by clicking the "master" dropdown menu and typing your new branch name in, or by clicking on branches and then selecting "New branch". I called mine
linear-algebra-beta.
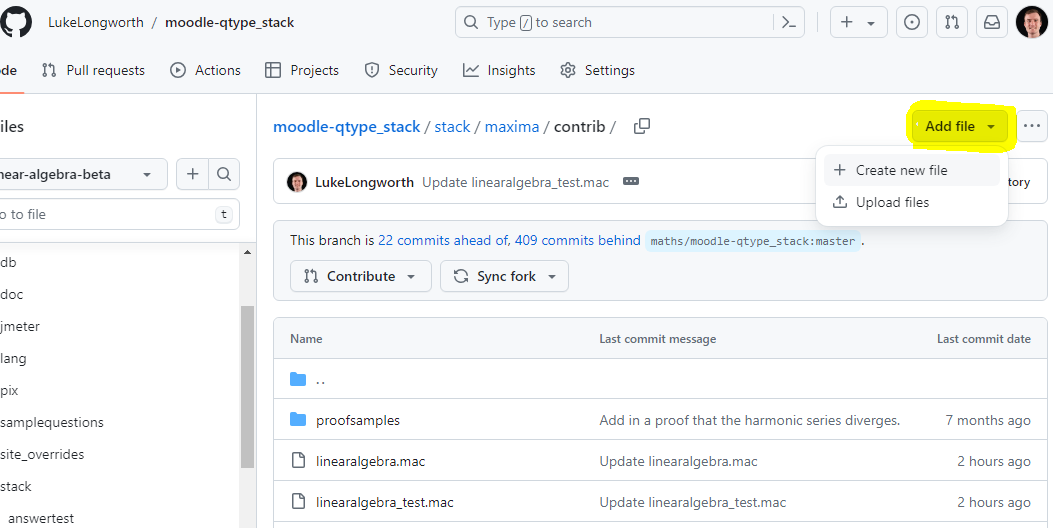
- From this branch, navigate to stack/maxima/contrib, and click "Add file". In my case, I simply created a new file called
linearalgebra.mac.
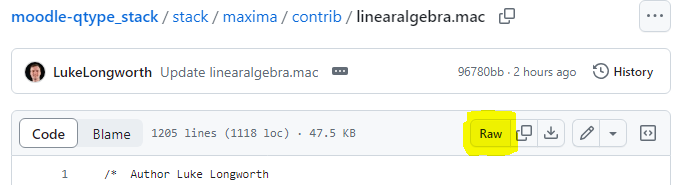
- Now, once you've created the file and committed the changes, you can click the "Raw" button when viewing the code, and copy this URL into a STACK question to get access to this code. In my case, I have been using
stack_include("https://raw.githubusercontent.com/LukeLongworth/moodle-qtype_stack/linear-algebra-beta/stack/maxima/contrib/linearalgebra.mac");at the beginning of my questions, and will eventually transition it tostack_include_contrib("linearalgebra.mac")when this file is published to STACK properly.
This is where my work was stored, but when writing individual functions it's nicer to get some more immediate responses to check that everything is working properly. Rather than going back to my single STACK question with horrible load times, I used the following workaround:
3. Send to CAS
This is twisting the intended use case of this function a bit, but it has worked excellently for me. I often use the "Send general feedback to the CAS" link for quick-and-dirty testing in a real STACK environment. You can access this link from the STACK question dashboard (I have an empty question bookmarked for this). You can edit the question variables and general feedback fields of a question temporarily, and even use stack_include.
My main workflow was to include this header:
simp: false;
tests: [];
s_test_case(sa,ta):= tests: append(tests,[[is(sa=ta),sa,ta]])
followed by either stack_include or simply a copy-paste of the code I'm wanting to check, and then I would put the following into the General Feedback field:
[[foreach test="tests"]]
{@first(test)@} {#second(test)#} {#third(test)#}<br><br>
[[/foreach]]
As I added more to the code, I would use s_test_case(sa,ta) with sa being the function application and ta being the expected output. This was a really useful way to build test cases into the development process. The three lines setting simp and dealing with s_test_case shouldn't be included in the final file, these are just for testing.
4. Test cases and documentation
Test cases are important to ensure that small edits to this open source software don't have unintended effects. These are important for the main codebase of STACK, but in the event that a new version of STACK would break existing questions, users can anticipate this before the upgrade. The stack_include feature copies the source code from the chosen file in the contrib folder and pastes it directly into the question when compiling (usually this means when you click Save). This means that this code is independent of the version of STACK you are running, and changes made to these files can impact other users without them knowing*. Detailed test cases are therefore particularly important here!
*Note: Any edits to files like linearalgebra.mac will only affect existing questions when they are compiled (saved), so you won't be immediately breaking existing questions/quizzes by editing these files. Caution should still be taken!
At present, test cases are kept separately from the main function. For example, I am currently maintaining both linearalgebra.mac and linearalgebra_test.mac, the latter of which hosts the test cases. The test cases should all be of the form s_test_case(test case, expected output). For example, one of my functions has the following set of test cases:
s_test_case(diagmatrix_like([1,1,1],3,3),ident(3));
s_test_case(diagmatrix_like([1,2,3],3,4),matrix([1,0,0,0],[0,2,0,0],[0,0,3,0]));
s_test_case(diagmatrix_like([1,2,3],4,3),matrix([1,0,0],[0,2,0],[0,0,3],[0,0,0]));
s_test_case(diagmatrix_like([1,2,3],4,4),matrix([1,0,0,0],[0,2,0,0],[0,0,3,0],[0,0,0,0]));
s_test_case(diagmatrix_like([1,2,3],2,3),matrix([1,0,0],[0,2,0]));
s_test_case(diagmatrix_like([1,2,3],3,2),matrix([1,0],[0,2],[0,0]));
diagmatrix_like(L,m,n) constructs a mxn matrix with the entries of L on the diagonal. I chose those test cases to cover all of the possible cases I could think of: a square matrix with a full diagonal, tall and squat matrices with full diagonals, a too-short list of given diagonal entries, and over-full lists of diagonal entries with rectangular matrices.
Documentation should be in the main file. This is an ongoing project, so the format is not finalised. At present, I have been following the format of
/**
* Description of function
*
* @param[data type] parameter_1_name Description of parameter
* @param[data type] parameter_2_name Description of parameter
* @return[data type] Description of returned value
*/
One specific example is shown below for a function that takes a matrix and vector and returns the general solution:
/**
* Solve the matrix equation Ax = b given matrix A and column vector (or list) b.
* Optionally will find a least squares solution
* Always returns a general solution if one exists, even in the least squares case
* If a single solution is required, use pseudoinverse(A) . b instead.
*
* @param[matrix] A An mxn matrix
* @param[matrix] b A mx1 matrix (or a list with m entries)
* @param[boolean] lstsq Optional: if given true then a least squares solution will be obtained. If false or omitted, only exact solutions obtained.
* @return[matrix] The general solution to Ax = b. If no solution exists and lstsq is not true, then matrix([]) is returned.
*/
mat_solve(A,b,[lstsq]):= block([m,n,vars,eqns,sol],
... function here ...
);
What does this file contain?
1. Functions about form
The first thing that appears is the c and r functions. These are inert functions that students and teachers can use to represent column and row vectors respectively, and the validation box will correctly display them. This allows students to write expressions containing vectors without needing to use Maxima's matrix notation.
The LaTeX formatting is done using texput to extract the arguments, format them individually using tex1, and then put them all together within appropriate LaTeX matrix wrapping. The two functions are also declared nonscalar, so that expressions like c(1,2) + matrix([3],[4]) will simplify to matrix([4],[6]) rather than matrix([3 + c(1,2)],[4 + c(1,2)]).

As of STACK v4.6.0, only direct texput commands in the Question Variables are picked up by the validation to change the LaTeX display. This means that you cannot put the texput inside a larger block of code (notably, including if statements) or refer to other existing variables, functions or flags within the texput code itself. Ideally, teachers would be able to choose whether to include this part of the file with a flag variable (in case they are wanting to use the variable c for a constant of integration, or r to refer to the vector [x,y,z] etc.), but this is not possible. Even nicer would be the ability to choose what type of matrix bracket is used (questions that ask for lists of vectors are a bit confusing to read at present), or to match the question-wide matrix bracket choice. Perhaps future versions will give more control over texput and validation, but for now these suffice.
There are also a number of functions that convert statements between various "standard forms". It is much easier to write this library of routines knowing that everything is either a list of lists or a matrix. Convenience functions are provided that will convert groups (i.e. lists, sets, ntuples, spans, and others) of vectors (matrices, c, r, lists, ntuples) into a list of lists, and then to convert a list of lists into a matrix.
2. Predicates
Predicates are exceptionally useful little tools to use in PRTs or inside larger routines to avoid unwanted error messages. There are not many Maxima-native predicates to do with linear algebra outside of matrixp, zeromatrixp and blockmatrixp, and there are many properties of matrices we may want to check. There are many predicates here that teachers can use to quickly check properties of student answers, or that they can use to filter out answers of unexpected form.
There are also a handful of comparison functions that test some sort of equivalence between a teacher's answer and a student's answer. These are mostly to do with equivalence of subspaces and linear independence, as algebraic equivalence is too restrictive to test these properties.
3. Useful functions for manipulating matrices, collections of vectors, or algebraic expressions containing vectors.
This is too varied to explain in detail here. Interested parties should look at the file itself to see what sort of capabilities it has. In future I hope to write a detailed set of documentation including examples of use.
4. Matrix Factorisations
This one is a little self-indulgent, as it usually makes little sense to find exact representations of a matrix QR factorisation, SVD, or diagonalisation unless the matrix has been set up explicitly to produce nice answers in this case. In EMTH211, we use Python to find solutions to these generic cases. I can't think of any cases where these functions are likely to be that useful, but it felt wrong to write a linear algebra package and not include these common factorisations.
Some surprises and pitfalls
The inclusion should work for simp:false and simp:true and return appropriate results in either case. This caused me a few headaches, as I forgot to work with simp:false for a large chunk of the original writing process. I only noticed when I went back through to add test cases the first time and realised that everything broke. Some things to watch out for:
makelistdoesn't work in expected ways withsimp:false. Rather thanexpr: makelist(func(i),i,1,n)you might preferexpr: map(lambda([ex], func(ex)), ev(makelist(i,i,1,n),simp))- For loops don't automatically evaluate the indexing variable, so you might encounter errors when, for example,
i = i+1instead of the expectedi = 2. To avoid this, you can simply includei: ev(i, simp)at the beginning of the loop. - Some functions, particularly predicate functions, require their inputs to be simplified before they work. For example, I found that
zeromatrixp(apply(matrix,[[0,0,0]]))was returningfalseeven thoughapply(matrix,[[0,0,0]])will correctly return a matrix of zeros. I fixed this withzeromatrixp(ev(apply(matrix,[[0,0,0]]),simp)). - My version of
s_test_casedidn't quite work as intended in all instances. I don't want things to be forcibly simplified before comparing, and this led to what I suspect is a similar issue to the above problem, wheresaandtawould print identically, butis(sa=ta)would return false. This typically happened when comparing lists or matrices, or when variables like%r1or%r2were generated in an answer. In these instances, I ignored the false flag ifsaandtaseemed the same.
There were also design consequences I didn't initially expect. For example, as mentioned above, there are many matrix factorisations included in the file simply for completeness' sake, but I don't think they are very useful for designing STACK questions. A good question that concerns itself with matrix factorisations would begin by generating the factors and multiplying them out to get the desired matrix. This ensures that the matrix has the properties you expect, and that students can easily compute and type in their answer without needing to deal with an absurd amount of simplification. If you are getting students to practice finding a SVD for any given randomly generated matrix, then I personally don't believe you should be using STACK (try CodeRunner!).
A related problem appears when trying to make functions that are too all-encompassing. For example, I originally wanted to make a function that would check whether two given vector parametric equations were equivalent to one another. For example, is c(1,2) + t*(3,4) equivalent to c(-2,-2) + t*(-6,-8)? I was halfway through writing the function when I realised that in a real question I would rather individually check all of the components; has the student given me an answer in a sensible form, is the student's direction vector pointing in the right direction, and is their fixed point actually on the line? Then I can give targeted feedback to the student such as "your line is parallel to the correct answer". Therefore, I simply provided a function to extract each of these components and will leave the teacher to mark them appropriately.
I initially wanted to include some randomisation functions such as rand_orth to generate a random orthogonal matrix, or rand_integer_invertible to generate a random integer matrix whose inverse is also populated by only integers, both of which would be very useful to me. However, it became very clear very quickly that I want much finer control than what a general function like this could produce. For example, I tried writing a question that asks students to find all eigenvalues and eigenvectors of a 3 by 3 matrix from scratch. This is quite a lot of work, especially when we don't include factorising a cubic as a learning objective in our course, so my list of desired properties for the matrix became: An integer matrix with small integer eigenvalues, simple eigenvectors, and two off-diagonal zeros in the same row or column. Another example was writing a factorisation question; it is not enough to generate a random orthogonal matrix, optionally remove some columns, and multiply it by a random upper triangular matrix. The resulting product will have horrible entries and be unusuable in most cases. Ultimately I concluded that this was a futile** task outside the scope of this project, but I may revisit it in the future.
**Note: I have since worked on this a bit more and decided that there are sensible ways to do this when assuming that teachers will correctly use deployed variants, and am considering publishing rand_matrix.mac as a separate file.
Final reflections and conclusions
If I were to begin this project again, I think I would start with writing the quizzes. That way, my motivation to add something to linearalgebra.mac would be noticing myself doing something that felt both annoying to code and broadly applicable. It would mean that I would inevitably need to do a second pass over the question bank at the end, but I think it would keep the project more focused. Feature creep was a big issue for me to deal with, and I'm not convinced that everything I wrote will turn out to be useful. Perhaps I should split this into multiple smaller files, but there is so much inter-dependency that only a few functions could reasonably be extracted without flow-on consequences.
In fact, it has become increasingly clear that what I have done with linearalgebra.mac is somewhat outside the intended scope of of stack_include_contrib. This function simply pastes the included code into the question variables as if the user typed them in. Users cannot pick and choose which features they want, and contributions cannot use banned functions like error.
I think that stack_include_contrib is working as intended here and doesn't need large-scale changes. In fact, the knowledge that anyone who uses this file in the future will be going out of their way to include it gave me some comfort: the intended users are already comfortable using STACK. It gave me freedom to just make something that works and then tidy it up later. Furthermore, this process of (1) identifying a limitation, (2) writing some code that fixes the problem, (3) generalising the code for wider use, and (4) adding it to the contrib folder leads very naturally to a step (5): pick out key features that are particularly broadly applicable and work with the lead developers to add them to core STACK. I hope that in future some of these features, particularly the vector input, augmented matrix, and predicate functions could be modified and added to the basic STACK install for long-term support. I would recommend this process to anyone who has some experience working with Maxima code but is not confident working directly on an open-source project like this.